Discover High-Performance AI Models.
Maximize ROI.
Test AI models from external vendors directly on your data — without ever exposing it. Identify top performing models and boost ROI across your use cases.
How tracebloc works
trusted by
Easily test which vendor models perform best —
on your data, for your use cases
on your data, for your use cases


Easily test which vendor models perform best —
on your data, for your use cases
on your data, for your use cases


Discover the best-performing AI models — maximize ROI

Discover the best-performing AI models — maximize ROI

Keep
your data and IP
private and protected — stay in full control
private and protected — stay in full control

Keep
your data and IP
private and protected — stay in full control
private and protected — stay in full control

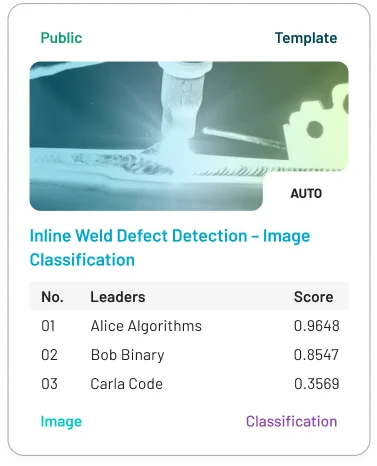
Start fast with ready-to-use templates
Explore a template, accelerate setup, and test the platform by training and benchmarking a model
How to setup your first AI use case
Set up your first use case, onboard vendors, and evaluate their models securely.
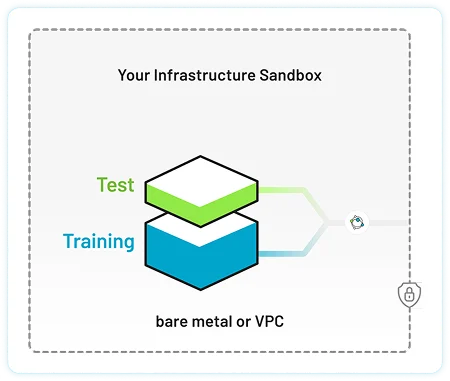
Set up secure environment
Deploy an isolated Kubernetes cluster in your cloud (VPC) or on bare metal. Pull the tracebloc client from Docker Hub and connect it to our backend.
Ingest training and test data
Ingest your datasets into the secure environment. A meta representation will be displayed in the web app; your data always stays local.
Define use case
Create your use case, select datasets, pick a predefined benchmark or define your own, and add an EDA and description to guide vendors.
Invite vendors & allocate compute
Invite vendors via email whitelisting. Assign compute budgets per use in Flops. Vendors can submit any model architecture compatible with TensorFlow or PyTorch.
Train & fine-tune on your infrastructure
Vendors fine-tune models inside your isolated Kubernetes environment. Your data and fine-tuned weights never leave your infrastructure.
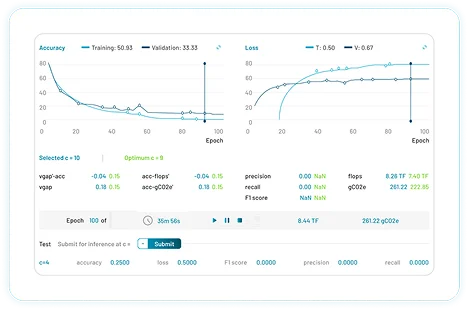
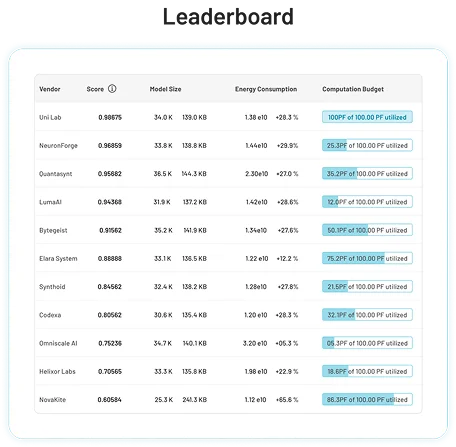
Benchmark and discover best-performing model
Evaluate models on e.g. accuracy, latency, and robustness, efficiency, gCO₂e. Select the best model, negotiate usage terms with vendor, and hand over to your MLOps team.
Pricing
Pay only for what's used — pricing is based on the compute your vendors consume when training, fine-tuning, or benchmarking models on your infrastructure
FAQs
Answers to common questions
Business & Use Case
Business & Use Case
IT & Security
Training, Compute & Models
Data, IP & Compliance
Who typically uses tracebloc inside company?
• Business teams -> model performance as a direct effect on the top or bottom line
• Procurement teams -> preselect and technically evaluate potential vendors
• Research teams -> more closely collaborate with other external researchers
• Engineering teams -> protecting data and IP
What kind of ROI can we expect from using tracebloc?
Can we use tracebloc for vendor selection?
How does tracebloc fit into our procurement process?
Is tracebloc a consulting service or a product?
Can we reuse evaluation setups for future tenders?
Do we need to sign a long-term contract?
How does tracebloc help reduce vendor lock-in?
How long does it take to set up a use case?
Can we run multiple use cases at once?
Can non-technical stakeholders understand evaluation results?
Can we reuse pipelines across similar use cases?
Can we collaborate with public research institutes?
Who typically uses tracebloc inside company?
• Business teams -> model performance as a direct effect on the top or bottom line
• Procurement teams -> preselect and technically evaluate potential vendors
• Research teams -> more closely collaborate with other external researchers
• Engineering teams -> protecting data and IP
What kind of ROI can we expect from using tracebloc?
Can we use tracebloc for vendor selection?
How does tracebloc fit into our procurement process?
Is tracebloc a consulting service or a product?
Can we reuse evaluation setups for future tenders?
Do we need to sign a long-term contract?
How does tracebloc help reduce vendor lock-in?
How long does it take to set up a use case?
Can we run multiple use cases at once?
Can non-technical stakeholders understand evaluation results?
Can we reuse pipelines across similar use cases?
Can we collaborate with public research institutes?