Benchmark AI models
on your own data
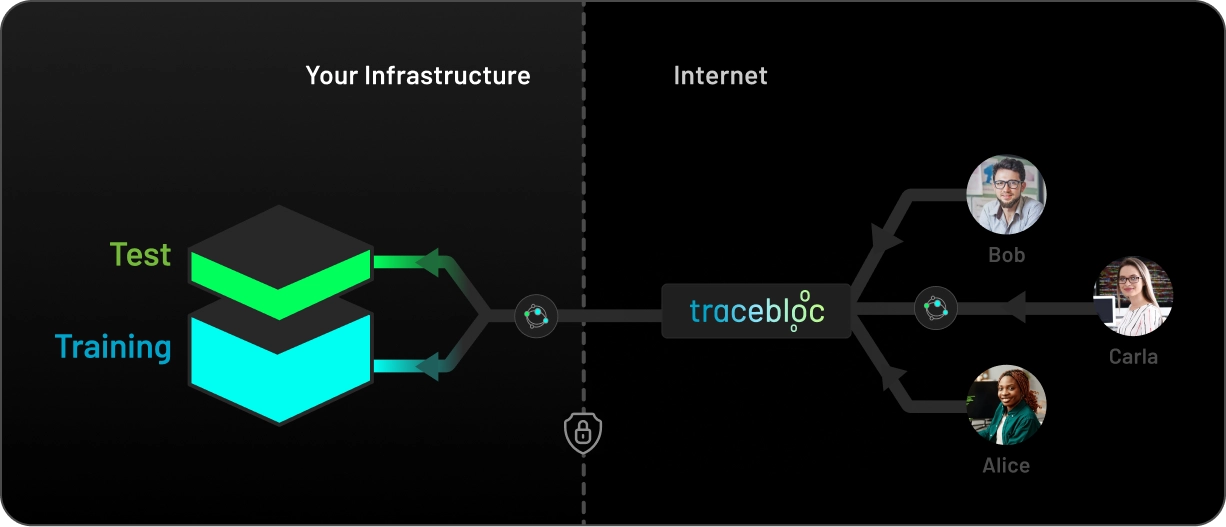
Test AI models from anyone — your team, vendors, research partners — directly on your infrastructure, against your training and test data. Nothing is ever exposed.
how tracebloc works
trusted by




Any model, any framework, running in your infrastructure
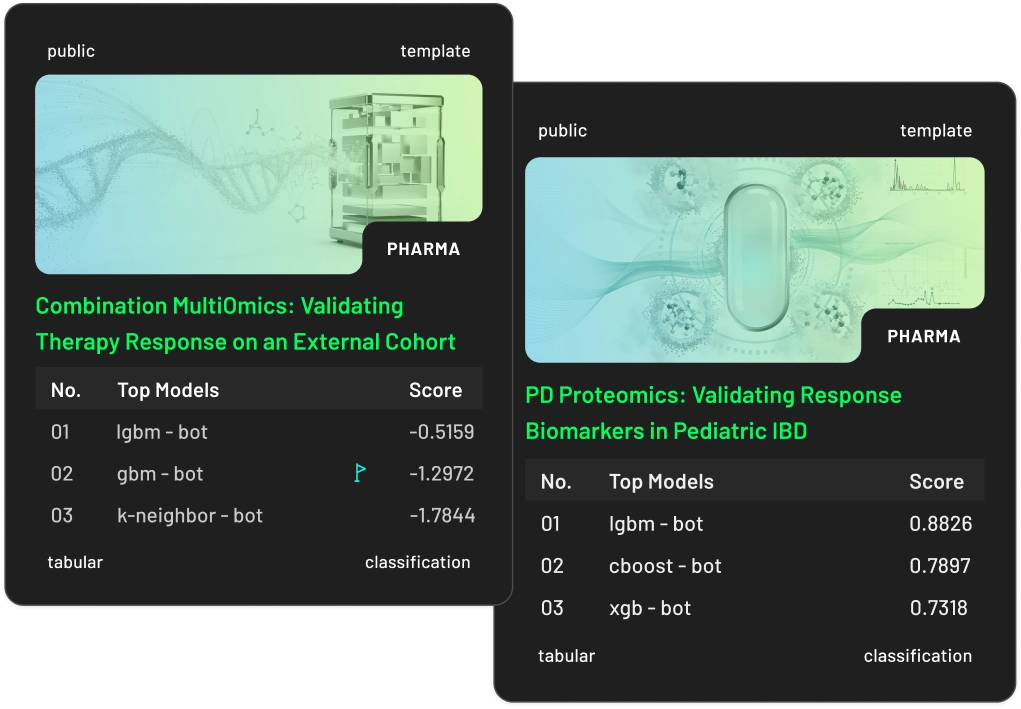
See how every model ranks on your task
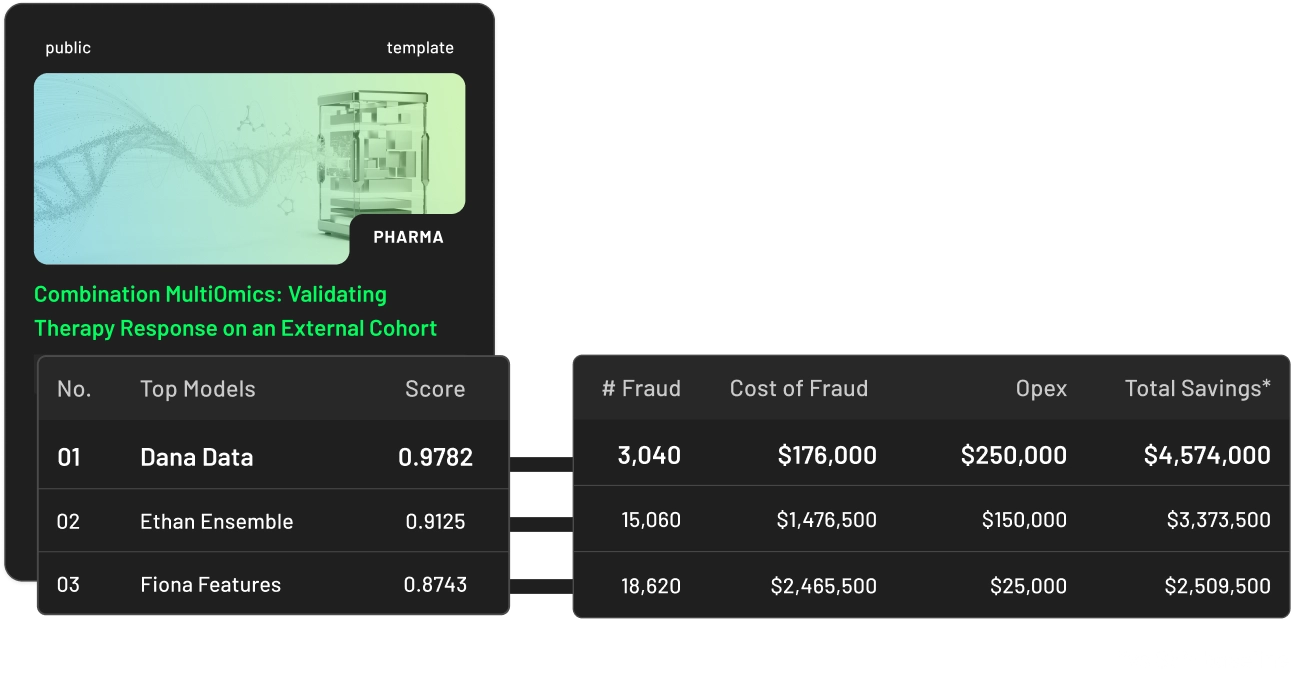
Your data never leaves
your infrastructure
WHAT TEAMS BUILD
Active use cases on private data
Setup
Set up your first use case, onboard vendors
1
2
# Installs everything. Live in minutes 🤟
$ bash <(curl -fsSL tracebloc.io/i)
1
2
# Installs everything. Live in minutes 🤟
irm https://tracebloc.io/i.ps1 | iex
Deploy tracebloc in your environment
Install on any cloud, any on-prem, or any Kubernetes cluster. Runs on Docker. Setup in about 30 minutes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from tracebloc_ingestor import Config, Database, APIClient, CSVIngestor from tracebloc_ingestor.process.base import BaseProcessor from tracebloc_ingestor.utils.logging import setup_logging from tracebloc_ingestor.utils.constants import DataCategory, Intent # Initialize config and configure logging config = Config() setup_logging(config) logger = logging.getLogger(__name__) class ImageResizeProcessor(BaseProcessor): """Processor for handling image data in records. This processor resizes images to a target size while maintaining aspect ratio, and extracts image metadata. It supports both binary and file- based processing. """ def __init__(self, config: Config, target_size: tuple = (800, 800), storage_path: Optional[str] = None): self._processed_files = set() # Track processed files for cleanup ...
Ingest your training and test data
Your data stays on your infrastructure. tracebloc sees only metadata, never raw records. Bring any format — structured, unstructured, or mixed.
PHARMA
Prognostic Transcriptomics: Progression Biomarkers in Neuromuscular Disease
Define the task and metrics
Pick the task. Pick what counts — accuracy, latency, cost, or a custom metric. One config, applied consistently across every submission.
Invite other data scientist, colleagues, vendors or AI experts
Invitation Sent!
Invite contributors to submit models
Your team, vendors, or research partners can each submit models — open-weight, fine-tuned, or proprietary. Every submission runs in its own isolated container.

Every model runs in parallel
Contributors train and benchmark inside identical containers on your compute. Same data, same pipeline, same metrics — no manual coordination needed.
Leaderboard
See the leaderboard
Ranked by accuracy, latency, and cost per request. Exportable. Share with your team, your paper, or your procurement process.
Deploy tracebloc in your environment
Install on any cloud, any on-prem, or any Kubernetes cluster. Runs on Docker. Setup in about 30 minutes.
Ingest your training and test data
Your data stays on your infrastructure. tracebloc sees only metadata, never raw records. Bring any format — structured, unstructured, or mixed.
Define the task and metrics
Pick the task. Pick what counts — accuracy, latency, cost, or a custom metric. One config, applied consistently across every submission.
Invite contributors to submit models
Your team, vendors, or research partners can each submit models — open-weight, fine-tuned, or proprietary. Every submission runs in its own isolated container.
Every model runs in parallel
Contributors train and benchmark inside identical containers on your compute. Same data, same pipeline, same metrics — no manual coordination needed.
See the leaderboard
Ranked by accuracy, latency, and cost per request. Exportable. Share with your team, your paper, or your procurement process.
1
2
# Installs everything. Live in minutes 🤟
$ bash <(curl -fsSL tracebloc.io/i)
1
2
# Installs everything. Live in minutes 🤟
irm https://tracebloc.io/i.ps1 | iex
FAQs
Answers to common questions
The best tools for evaluating AI models in 2025 run benchmarks on your data, not public test datasets. Many frameworks are built for evaluating large language models or generative AI outputs you already own, often within the LangChain ecosystem or CI/CD integration pipelines. tracebloc solves a different problem: comparing models from multiple external vendors on your private data, side by side, without your data ever leaving your infrastructure.
Stay in the loop
Get updates on new templates, model releases worth testing, and community benchmarks. No spam, unsubscribe anytime