Federated Learning in Healthcare: The Implementation Guide
Explore real-world federated learning use cases in healthcare—from retinal disease screening to cardiovascular risk prediction.
Moritz Bertold
Mar 05, 2026
13 min
Why healthcare needs federated learning now
Healthcare organizations are caught between two competing priorities: using AI to improve patient outcomes, and keeping patient data private and secure. Traditional centralized approaches require moving petabytes of medical images, genomic sequences, and electronic health records (EHRs) between sites. This triggers compliance issues under GDPR, HIPAA, and national data sovereignty laws while being technically complex and financially prohibitive. (Rieke et al., 2020)
This also forces fragmented AI development. Each institution trains machine learning models on isolated local data, so resulting systems underperform when deployed to different patient populations.
Healthcare AI needs access to diverse data across demographics and clinical contexts to recognize patterns effectively. Privacy regulations make that data impossible to centralize.
Federated learning for healthcare informatics resolves this structural tension. Instead of moving datasets to a central location, machine learning models travel to where medical data already exists. Each site produces locally trained model updates and sends only encrypted model parameters back to a coordinating server without any health information leaving the institution. (McMahan et al., 2017) This architecture enables healthcare federated learning: collaborative model development across institutions while maintaining data sovereignty, privacy, and regulatory compliance.
Federated learning market, Grand View Research, 2024
What is federated learning in healthcare?
Federated learning healthcare applications operate through distributed training that keeps medical data local while building shared intelligence. (McMahan et al., 2017) A central orchestrator initializes a global model and distributes it to participating sites: university hospitals, national biobanks, or pharmaceutical research centers.
Parameter aggregation happens at the central server using secure protocols. No participant can reverse-engineer another institution's data from these parameters. The aggregated updates form an improved global model reflecting insights from all contributing datasets.
Federated learning market, Grand View Research, 2024
The cycle repeats iteratively. The enhanced global model returns to each site for another training round. It improves its ability to recognize patterns across diverse patient populations and protocols.
Privacy preservation operates at multiple layers:
- Secure aggregation prevents the server from seeing individual site updates (Bonawitz et al., 2017)
- Differential privacy adds mathematical guarantees against data inference (Abadi et al., 2016)
- Encryption protects model parameters in transit and at rest
- Access controls limit which systems can interact with the learning framework
The reasons healthcare needs federated learning
Federated learning was designed to solve a specific problem: valuable data that cannot move, institutions that need to collaborate but cannot share, and models that need diversity to perform but cannot access it. Healthcare does not just fit this profile. It defines it. (Rieke et al., 2020)
Regulatory pressure is where federated learning earns its first proof point. GDPR, HIPAA, and equivalent frameworks impose significant constraints on how patient data can be processed. Any data transfer between institutions requires legal agreements, de-identification processes, ethics approvals, and ongoing compliance monitoring.
For many organizations, that overhead makes centralized AI development impractical before a single line of training code is written. Federated learning does not work around these constraints — it operates within them by design. It makes compliance the starting condition rather than an obstacle to manage.
Data silos are where federated learning delivers its second proof point. Hospitals, biobanks, research consortia, and clinical registries each maintain separate systems with incompatible formats, different coding standards, and independent governance structures.
These silos are not just technical — they reflect legal and ownership boundaries that persist even when institutions want to collaborate. A hospital and a biobank may be willing to share insights but legally unable to share the data. Federated learning resolves this directly: collaboration happens across those boundaries without requiring the data to cross them.
The need for diverse datasets is where federated learning demonstrates its core technical advantage. A model trained at a research hospital will underperform when deployed at a clinic with different patient demographics, imaging equipment, and clinical protocols. This is not a minor calibration issue; it is a systematic failure mode that affects real patients. (Zhao et al., 2018)
Federated learning allows locally trained models to contribute to a shared global model. It learns from diverse data sources across institutions and geographies without any site relinquishing control of its raw data.
Rare disease research requires patient cohorts that no single institution can assemble on its own. Federated learning allows rare disease registries, research centers, and academic hospitals to contribute to the same model without pooling records. (Pati et al., 2022); (Chen et al., 2024) The result is training data with the breadth of a multi-site consortium and the governance simplicity of a single-site study.
Bias reduction is where federated learning makes its case for clinical reliability. When training data reflects a broader range of patient populations, equipment types, and clinical protocols, the resulting model is less likely to encode the demographic or procedural biases of any single contributing site. (Chen et al., 2023); (Poulain & Beheshti, 2023) In clinical AI applications where model failures carry patient risk, this matters more than in most other domains.
Benefits of federated learning in healthcare over centralized medical AI
The benefits of federated learning in healthcare are best understood through direct comparison with centralized approaches. Healthcare institutions increasingly prefer federated architectures because they preserve institutional autonomy while enabling collaborative intelligence.
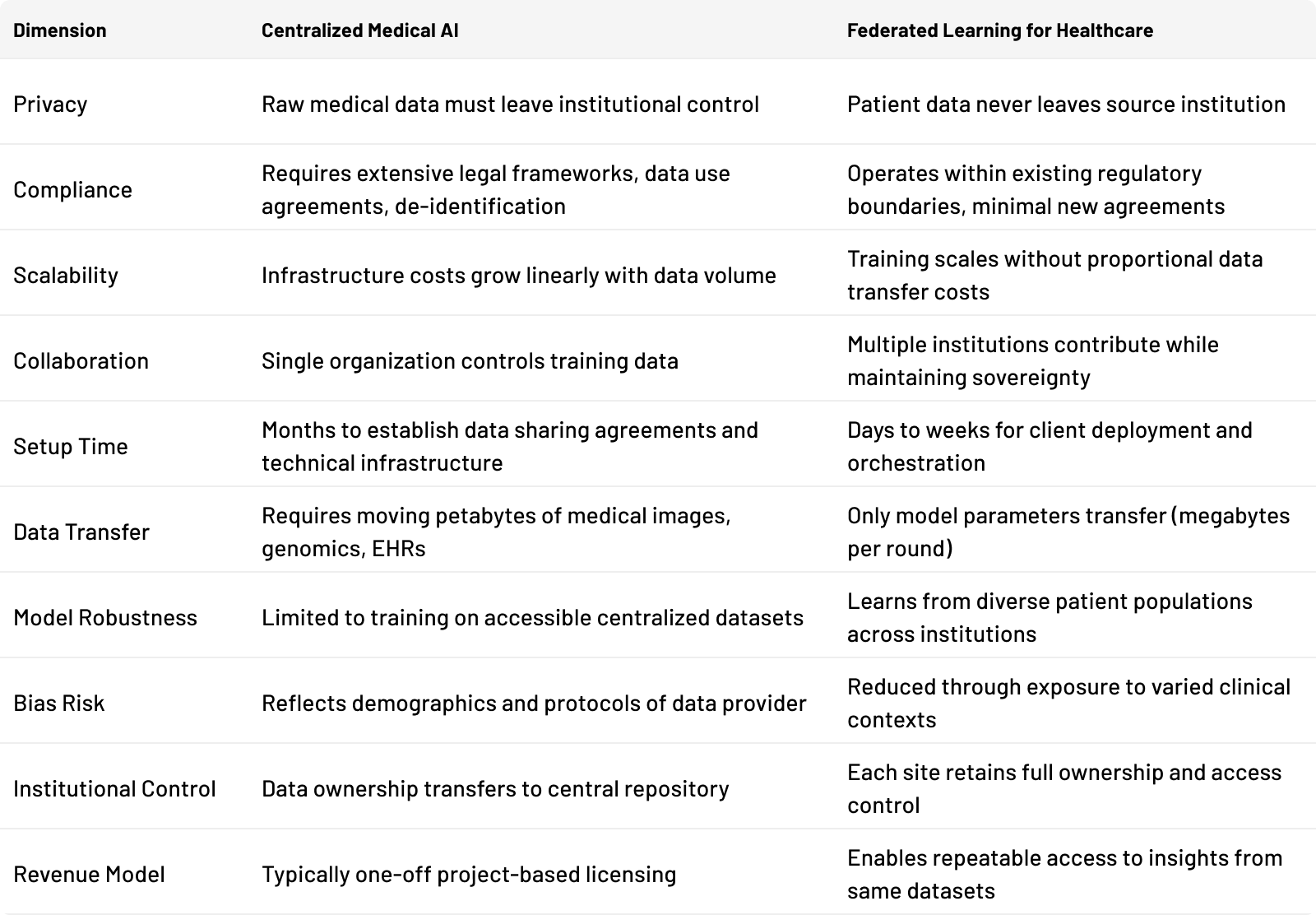
The table shows the architectural difference. But the real challenge isn't deciding if federated learning is better. It's figuring out how to adopt it without building the infrastructure from scratch.
tracebloc: The technological layer that makes it practical
Implementation traditionally requires months of infrastructure setup, custom security engineering, and complex orchestration. Some healthcare organizations lack the technical resources to build these systems from scratch.
tracebloc provides the technological layer that makes federated learning accessible without lengthy deployment timelines. The platform handles orchestration, encryption, secure aggregation, and compliance frameworks as built-in capabilities. Healthcare institutions connect their data infrastructure, select models, and begin distributed training within days rather than months.
Real-world federated learning healthcare AI use cases
The following use cases reflect actual deployments on the tracebloc platform. They address practical challenges faced by research institutes, hospitals, and pharmaceutical companies.
Federated Learning Applications in Healthcare You Can Try Right Now
Medical centers: Disease screening without data exposure
Medical centers evaluating AI systems for retinal disease detection need to validate vendor claims against their actual patient population without exposing proprietary imaging data. tracebloc allows institutions to invite AI vendors into secure environments within their own infrastructure. Each vendor's model operates in an isolated sandbox, processing retinal scans and returning performance metrics without accessing raw images. The institution receives standardized comparison data across all evaluated systems, enabling evidence-based vendor selection while maintaining complete data sovereignty.
See the complete retinal disease classification case: https://ai.tracebloc.io/explore/retinal-data
University hospitals: Cardiovascular risk prediction across distributed networks
University hospitals developing predictive modeling systems for heart disease risk assessment need diverse patient populations. Meanwhile, clinical data collection standards vary significantly across multi-site networks. (Khan et al., 2023)
tracebloc enables academic health systems to validate cardiovascular risk models across multiple participating sites while all patient records remain local. Each institution trains or evaluates the model using its own methodology, and updated model parameters are aggregated centrally. The resulting models learn from diverse populations and clinical practices without requiring data standardization or transfer.
View this cardiovascular risk prediction use case: [https://ai.tracebloc.io/explore/machine-learning-based-heart-disease-prediction)
Healthcare systems: Breast cancer screening AI vendor evaluation
Healthcare systems procuring AI for mammography screening must validate vendor claims against institutional data before committing. However, they can't expose medical imaging datasets to multiple external vendors. Research has demonstrated federated evaluation of oncology models across hospital networks as both technically feasible and clinically meaningful. (Ogier du Terrail et al., 2023)
tracebloc allows organizations to conduct parallel vendor evaluations within their own secure perimeter. Multiple AI vendors submit breast cancer detection trained models that run in isolated environments on institutional data. Vendors retrieve performance metrics but never access underlying patient scans, and the institution receives comparative reports specific to their patient population and imaging equipment.
Explore this breast cancer screening application: [https://ai.tracebloc.io/explore/ai-breast-cancer-screening-and-image-classification)
Research consortia: Secure multi-institution model validation
Research consortia frequently need to validate AI models across different patient cohorts without centralizing sensitive data. Large-scale federated validation — such as the FeTS initiative involving 71 sites across 6 continents — has demonstrated that models trained and validated in this way can match or exceed the performance of centralized approaches. (Pati et al., 2022) tracebloc allows external partners to run validation analyses locally on each institution's infrastructure.
The model visits the data rather than requiring data transfer. Each site evaluates model performance and contributes validation metrics to federated aggregation, producing results that reflect real-world variation across institutions and clinical contexts.
See how tracebloc powers secure collaboration in radiology: [https://ai.tracebloc.io/explore/finding-the-optimal-radiation-therapy-approach-along-the-prostate-cancer-patient-j )
Biobanks and life sciences: Repeatable pharma partnerships
University hospital, national biobanks, and disease registries face a structural funding challenge. Their revenue is capped by one-off data licensing deals while governance costs remain high. Traditional models require de-identification, data transfer, or costly setup for each pharma partnership. Once complete, the infrastructure does not scale to the next collaboration.
tracebloc changes this model. Biobanks can deliver insights, not data. External pharma partners run analyses locally on biobank infrastructure through isolated environments, with no de-identification required and no data leaving the institution.
Multiple customers can engage with the same cohort simultaneously, each in their own governed space. Recent work on federated genome-wide association studies demonstrates this can extend to biobank-scale genomic datasets. (Cho et al., 2025)
For biobanks managing funding sustainability beyond grant cycles, this creates a repeatable revenue model where clinical data becomes a recurring asset rather than a one-time transaction.
Challenges and limitations
Federated learning solves real problems, but it's not a silver bullet. Data heterogeneity, governance complexity, and institutional coordination challenges remain. Academic literature on federated learning documents these constraints thoroughly, (Xu et al., 2021) and organizations acknowledging them achieve better outcomes than those that do not. tracebloc addresses these challenges at the architectural level, though some inherent constraints require organizational as well as technical solutions.
Data heterogeneity
Medical imaging protocols vary by equipment and institutional preferences. Electronic health records use different coding systems and structures. These differences mean local datasets are non-IID (non-independent and identically distributed), which can slow model convergence compared to training on homogeneous centralized data. (Zhao et al., 2018); (Li et al., 2020)
tracebloc's metadataset capability gives participants statistical visibility into the data landscape, including size, class distribution, and quality scores, without exposing underlying records, allowing teams to assess data compatibility before training begins. Pre-built templates optimized for diverse healthcare data sources reduce the engineering burden of adapting algorithms to these conditions.
Communication overhead
Each training round requires transmitting model parameters between sites and the orchestrator. For deep learning models with millions of parameters, this creates bandwidth requirements that can strain network infrastructure. Compression and quantization strategies can significantly reduce this cost. (Konečný et al., 2016)
tracebloc's orchestration layer implements compression protocols automatically, monitors bandwidth usage across training rounds, and provides visibility into communication patterns — reducing what would otherwise require custom engineering.
Governance complexity
Each institution must establish data access agreements and approve model training protocols. Coordinating these processes across autonomous organizations requires dedicated project management.
tracebloc provides governance frameworks built into the platform: audit trails, access controls, and approval workflows that align with institutional review board requirements. Pre-configured templates reduce negotiation time by establishing clear protocols for data usage and model ownership from the start.
Security risks
Sophisticated attacks could potentially infer information about training data from model parameters. (Abadi et al., 2016); (Bonawitz et al., 2017)
tracebloc implements secure aggregation and encryption by default. Differential privacy mechanisms are available for organizations requiring additional guarantees based on their risk tolerance. These measures follow healthcare compliance standards without requiring security expertise from end users.
Institutional coordination
Participating sites must maintain compatible software versions and synchronize training schedules.
tracebloc's centralized orchestration manages version compatibility and training synchronization automatically. Monitoring dashboards show real-time status of all participating sites, and the orchestrator handles asynchronous participation so sites can contribute when available rather than requiring perfect synchronization.
How healthcare organizations deploy federated learning with tracebloc
Setting up federated learning infrastructure traditionally takes months. tracebloc changes this. Healthcare organizations deploy production-grade federated workflows in days using pre-built infrastructure with no custom engineering required.
-
Connect data locally.
Install the tracebloc client on existing infrastructure.<br />Medical images, genomic data, electronic health records, and training data remain in current storage systems. The client creates a secure connection layer enabling model training without data export. -
Select or upload models.
Teams choose from pre-built templates for specific healthcare applications or upload custom models developed internally or provided by pharmaceutical partners. -
Run distributed evaluation and training.
Computation begins with models training locally on medical data at each participating site, in parallel and within secure environments. The tracebloc orchestrator coordinates training rounds without accessing raw medical data. -
Compare results securely.
Each site generates performance metrics on its local patient population. Metrics flow back through encrypted channels. The platform aggregates results showing model performance across different clinical contexts without exposing underlying datasets. -
Aggregate performance metrics.
The orchestrator combines encrypted parameter updates from all sites using secure multi-party computation to create an improved global model. -
Deploy validated models.
After training converges and validation confirms acceptable performance, each institution decides independently whether to deploy the global model or a localized model adapted to their specific patient population and clinical workflows.
Built-in orchestration, metadata visibility, and performance tracking reduce the operational burden of managing multi-site collaborations, making federated learning healthcare applications accessible to institutions without dedicated ML infrastructure teams.
Future outlook for federated learning healthcare AI
Several converging trends are expanding the scope of healthcare federated learning. Regulatory evolution is the most immediate driver. The EU AI Act classifies clinical decision support as high-risk AI, requiring documentation and validation. (Busch et al., 2024) Federated architectures are well-positioned to support these requirements.
Privacy laws in additional jurisdictions continue to restrict centralized data handling, making approaches that keep medical data local increasingly attractive from a compliance standpoint rather than merely a technical one.
Precision medicine creates demand for models trained on large, genetically diverse patient populations. Published research on federated learning in healthcare documents how distributed frameworks enable genome-wide association studies and biomarker discovery across biobanks without creating centralized repositories. (Cho et al., 2025) A pharmaceutical company can validate a target across genomic datasets from multiple European biobanks without any institution transferring a single patient record. This model scales to global research participation while each country retains data sovereignty over its clinical data.
Edge medical AI is extending computational intelligence closer to clinical decision points, including wearable devices and point-of-care diagnostic tools. (Chen et al., 2020) Federated learning coordinates model training across these distributed environments, keeping health records on local devices or institutional systems while still contributing to shared model improvement. This has direct implications for remote patient monitoring and for healthcare delivery in regions with limited network infrastructure.
Continuous learning health systems build on this foundation by updating diagnostic models as new patient outcomes become available from clinical practice. Rather than periodic retraining on static datasets, models improve continuously as participating institutions contribute new data and outcomes, without requiring ongoing data transfer between sites. Healthcare federated learning is transitioning from a research methodology to standard infrastructure, reflecting a broader recognition that collaborative intelligence and patient privacy are complementary rather than competing requirements.
Strategic Takeaways
Federated learning in healthcare resolves the fundamental tension between collaborative AI development and patient privacy protection. (Rieke et al., 2020); (Dayan et al., 2021) Federated architectures enable both simultaneously by distributing model training across institutional boundaries while keeping medical data local.
Healthcare organizations gain several concrete strategic advantages:
- Participate in collaborative research without surrendering data ownership
- Validate external AI models without exposing protected patient information
- Benchmark diagnostic performance against peer institutions without compliance risk
- Monetize medical datasets through repeatable insight delivery to pharma partners
Technical barriers are decreasing. Communication protocols are more efficient, (Konečný et al., 2016) security mechanisms are better understood, and platforms like tracebloc reduce implementation complexity from months to days. The federated learning healthcare applications documented in research are no longer theoretical: they are running in production across hospitals, biobanks, and research consortia today. What was a research prototype three years ago is now a data-driven procurement decision.
The shift also changes how institutions think about data assets. Under centralized models, a biobank's value is constrained by the compliance cost of each individual transfer. Under federated models, the same dataset can serve multiple pharma partners simultaneously, generating recurring insights without recurring governance overhead. Medical data becomes infrastructure rather than inventory — a durable, compounding asset rather than a one-time transaction.
For organizations with large proprietary medical datasets, regulatory constraints preventing data sharing, or multi-institutional research requirements, the question is no longer whether federated learning is viable. It is whether your organization has the infrastructure to participate. tracebloc removes that barrier.
Ready to implement federated learning in your healthcare organization? Explore tracebloc's ready-to-deploy healthcare use cases or connect with our team to discuss your specific requirements
Federated learning in healthcare research papers:
Abadi, M. et al. (2016). ACM CCS.
Bonawitz, K. et al. (2017). ACM CCS.
Busch, F. et al. (2024). npj Digital Medicine, 7, 210.
Chen, B. et al. (2024). IEEE/ACM TCBB, 21(4), 880–889.
Chen, R.J. et al. (2023). Nature Biomedical Engineering, 7(6), 719–742.
Chen, Y. et al. (2020). IEEE Intelligent Systems, 35(4), 83–93.
Cho, H. et al. (2025). Nature Genetics, 57, 809–814.
Dayan, I. et al. (2021). Nature Medicine, 27(10), 1735–1743.
Khan, M.A. et al. (2023). Diagnostics, 13(14), 2340.
Konečný, J. et al. (2016). arXiv:1610.05492.
Li, T. et al. (2020). MLSys. arXiv:1812.06127
McMahan, H.B. et al. (2017). AISTATS, PMLR 54, 1273–1282. arXiv:1602.05629
Ogier du Terrail, J. et al. (2023). Nature Medicine, 29(1), 135–146.
Pati, S. et al. (2022). Nature Communications, 13(1), 7346.
Poulain, R. & Beheshti, R. (2023). ACM FAccT.
Rieke, N. et al. (2020). npj Digital Medicine, 3(1), 119.
Sheller, M.J. et al. (2020). Scientific Reports, 10(1), 12598.
Xu, J. et al. (2021). Journal of Healthcare Informatics Research, 5, 1–19.
Zhao, Y. et al. (2018). arXiv:1806.00582.